
Metaが汎用性の高い生成AI活用の音声合成モデル「Voicebox」を発表しました。文脈内の学習により、オーディオ編集、サンプリング、スタイライズなど、特別に訓練されていない音声生成タスクを実行できるとのこと。今回はこのニュースをお伝えします。
Meta / Introducing Voicebox: The Most Versatile AI for Speech Generation
Meta Research / Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
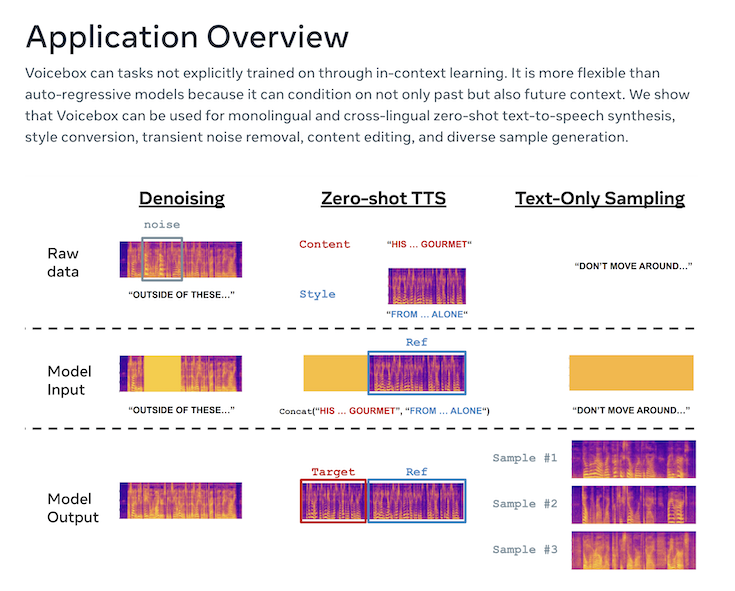
まずVoiceboxの特徴を紹介します。音声合成にとどまらず、音声編集、ノイズ除去、言語変換など多機能なことに驚きました。
■イン・コンテクスト音声合成
2秒程度の短い音声サンプルを使って、音声スタイルに合わせた音声合成を行うことが可能。わずか2秒程度のサンプルというは驚異的です。
■音声編集とノイズリダクション
音声全体を録音し直すことなく、ノイズに邪魔された音声の一部を再現したり、言い間違えた単語を置き換えたりすることができます。例えば、犬の鳴き声に邪魔された音声の一部を切り取り、Voiceboxにその部分を再生成するよう指示することができます。
これはポッドキャスト収録などで活用したくなる機能ですね。
■言語横断的なスタイル変換
英語、フランス語、ドイツ語、スペイン語、ポーランド語、ポルトガル語のテキストとスピーチのサンプルがあれば、サンプルとテキストが異なる言語であっても、Voiceboxはそれらの言語のテキストの音声合成が可能とのこと。例えば、英語で話した音声データを同じ声のテイストで、フランス語にした音声データに変換できるというわけです。現時点では、日本語に対応はしていませんが、日本語で話したデータが英語に変換できたら、ポッドキャスターの海外展開も容易になりそうで夢がありますね。
■多様な音声サンプリング
音声生成のデータを、多様なデータから学習することができることで、より効率よく精度を高めることが可能になったとのこと。
続いて、Voiceboxの仕組みを簡単に紹介します。
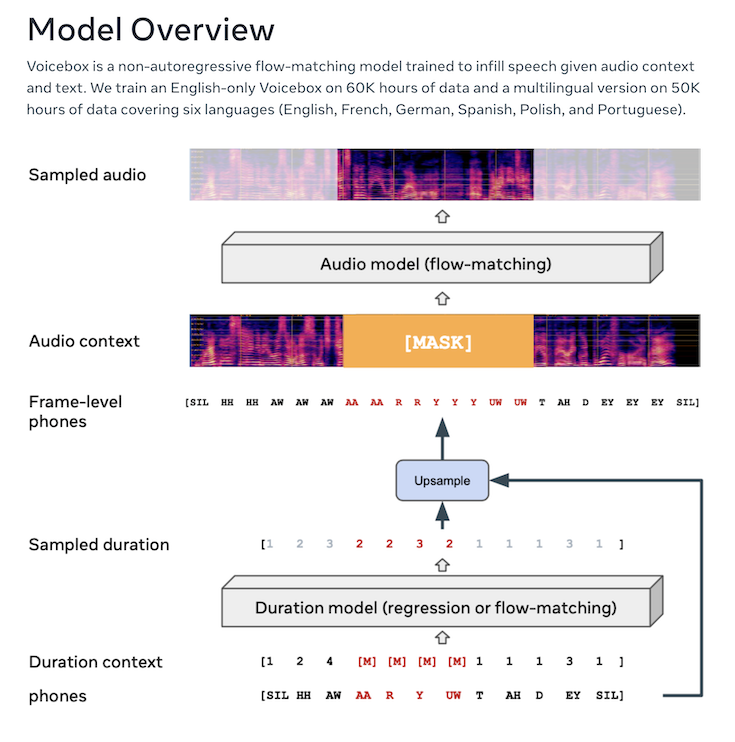
Voicebox以前の音声合成AIは、入念に準備されたデータを用いて、タスクごとに特定の学習を行う必要がありました。一方、Voiceboxは、非自己回帰的生成モデルである「Flow Matching」をベースに構築し、テキストと音声を非決定性マッピングによりラベル付けなしで学習可能な仕組みになっているとのこと。英語、フランス語、スペイン語、ドイツ語、ポーランド語、ポルトガル語のパブリックドメインオーディオブックに収録された5万時間以上の録音音声とトランスクリプトを使用して学習した結果、ゼロショット音声合成において、現在の最新英語モデルVALL-Eを、明瞭度と音声類似度の両方で上回り、さらに20倍もの高速化を実現できたそうです。
モデルの概要
アプリケーションの概要
なおこの音声AIは悪用される可能性があるため、Metaは現時点ではVoiceboxのモデルやコードを一般に公開していません。仕組みを解説する論文と、サンプルデータの公開までとなっています。懸念は確かにありますが、ポッドキャストのポストプロダクション工程においても非常に有用なツールとなりそうで、製品版の登場を心待ちにしたいところです。
ではまた。

