
Metaが1,100以上の言語に対応する大規模な音声AIモデル「Massively Multilingual Speech (MMS)」を発表しました。OpenAIのWhisperに対抗する音声AIモデルとして注目度も高いサービスになると思いますので、今回はこのサービスを簡単に紹介します。
Meta / Introducing speech-to-text, text-to-speech, and more for 1,100+ languages
Meta / Preserving the World’s Language Diversity Through AI
Today we're sharing new progress on our AI speech work. Our Massively Multilingual Speech (MMS) project has now scaled speech-to-text & text-to-speech to support over 1,100 languages — a 10x increase from previous work.
Details + access to new pretrained models ⬇️
— Meta AI (@MetaAI) May 22, 2023
今回Metaが発表した「Massively Multilingual Speech (以下MMS)」の特徴は、1,100以上の言語に対応していることにあります。既存の音声モデルは、地球上で話されている7,000以上の言語のうち、100言語程度のみをカバーするものでした。
新たな言語の音声モデルを構築するためには、大量のラベル付きデータとして、何千時間もの音声と書き起こしが必要になります。しかし問題なのは、ほとんどの言語では必要なデータが存在していないことです。しかも、わたしたちが生きている間に半分近くの言語が失われる危険性があるといいます。
これらの課題を解決すべくMetaのMMSは、自己教師あり学習「wav2vec 2.0」、1,100以上の言語のラベル付きデータ、4,000近い言語のラベルなしデータを組み合わせることによって対応言語数を増やす取り組みを行ったとのこと。興味深いのは、データの一部には宗教的なテキストとして新約聖書などを活用したとのこと。聖書は世界各国さまざまな言語で翻訳されており、さらにそれを朗読するデータも多く公開されているためデータセットとして有用だったそうです。
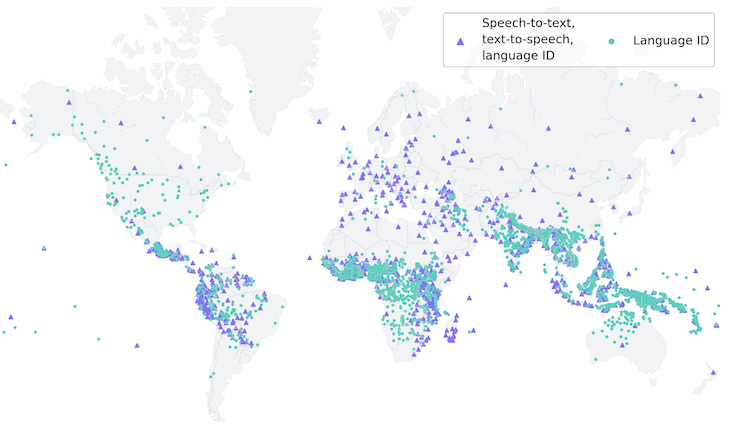
(音声認識・合成が可能な言語は紫色の三角形、識別できる言語は緑色の丸)
この結果MMSでは、音声認識・音声合成を従来の約100言語から10倍以上の1,107言語に拡張、言語識別についても従来の40倍以上の4,000言語以上に拡張できたとのこと。
今回の発表ではさまざまなデータの検証結果も紹介されました。
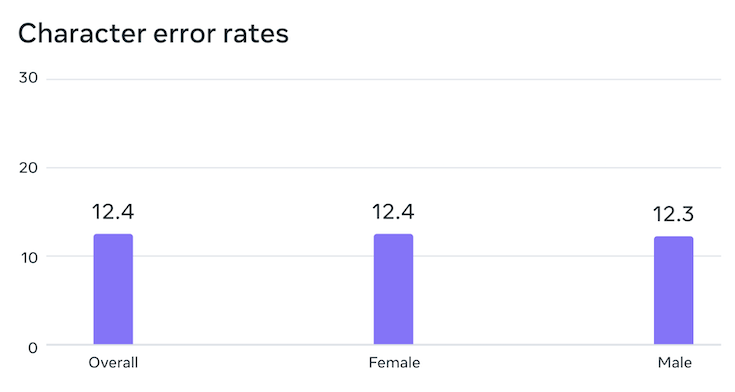
音声認識について、元のデータは男性の声が多かったものの、MMSでの検証結果は男性話者と女性話者の文字単位のエラー率はほぼ変わりなく、潜在的なジェンダーバイアスはないと言えることがわかったそうです。
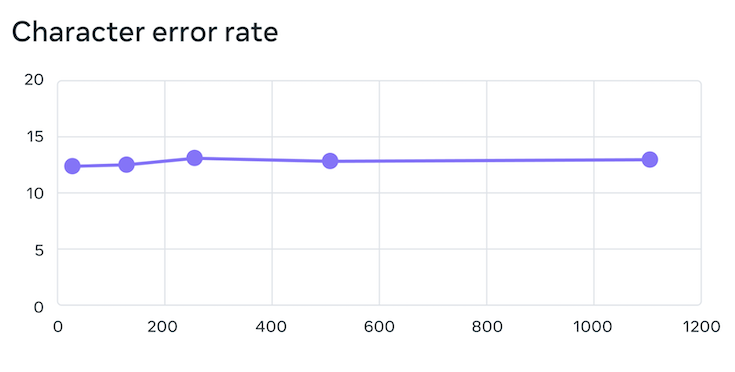
文字単位のエラー率は、通常対応する言語数が増えるにつれて性能は低下する傾向にありますが、MMSの場合は61言語から18倍以上の1,107言語に増やしても、エラー率は約0.4%しか増加しませんでした。
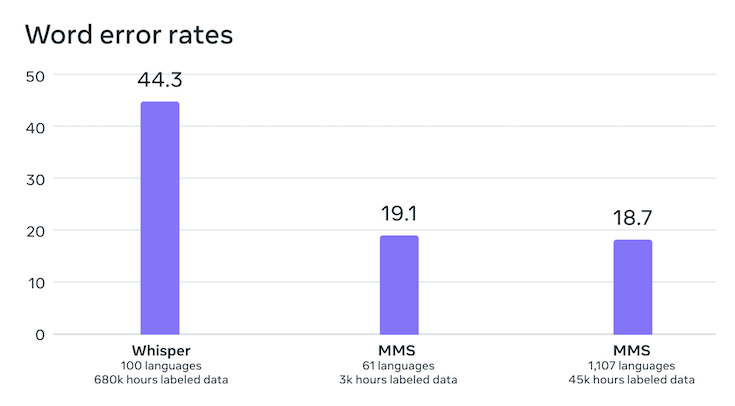
単語単位のエラー率をMMSとOpenAIのWhisperと比較した結果も公開されました。Whisperに比べて、エラー率が半分に低下したことがわかります。対応言語数は11倍多いにもかかわらず、より性能が高いのはすごいです。
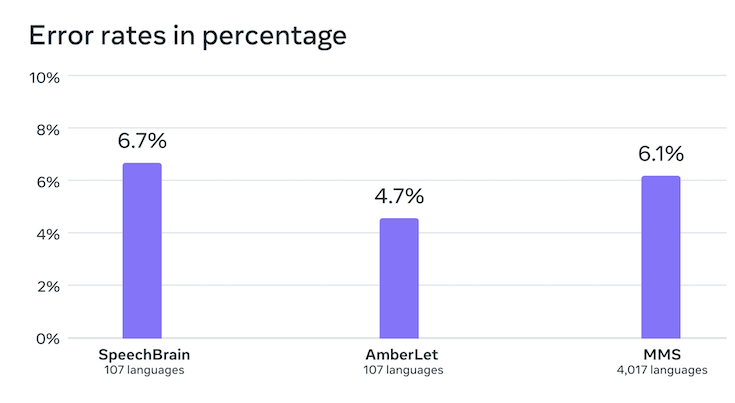
言語識別の精度についても、100言語に対応する既存サービスに比べて4,000言語を識別できるMMSのほうがエラー率が少ない結果となっています。
MMSは音声合成についても高い品質で1,100言語以上に対応できているとのこと。実際にデモ動画を聴いてみても全くわからない言語ですが、滑らかでリアルな感じがします。
今後さらに精度・品質を高め、対応言語を増やしていくために、より詳細の情報をまとめた論文と、GitHubも公開されています。興味のある方はあわせてご覧ください。
ではまた!

